When the Dataset you need is already in Domino and it’s shared with you, you can add it to your project and use it in your code.
To access the contents of an existing Dataset that is not in your project, mount the target Dataset in your project.
-
From the navigation pane, click Datasets, then click Mount Shared Dataset.
-
Click Dataset to Mount to see a list of Datasets to which you have access. Select the Dataset that you want to mount in this project.
To access a Dataset, you must be an owner, contributor, project importer, or results consumer on the project that contains the Dataset.
Under Shared Datasets, you can see the Dataset that you or someone else in the project mounted. The Path for the Dataset points to a directory where you will find the mounted Dataset in your project’s executions. When mounted this way, the Dataset as well as any associated snapshots are read-only.
-
Go to the Dataset that you want to unmount.
-
At the end of its row, click the three vertical dots and click Unmount.
|
Note
|
Unmounting a shared Dataset will not remove it from existing executions until the execution completes. However, the Dataset will not be available for new executions in this project. |
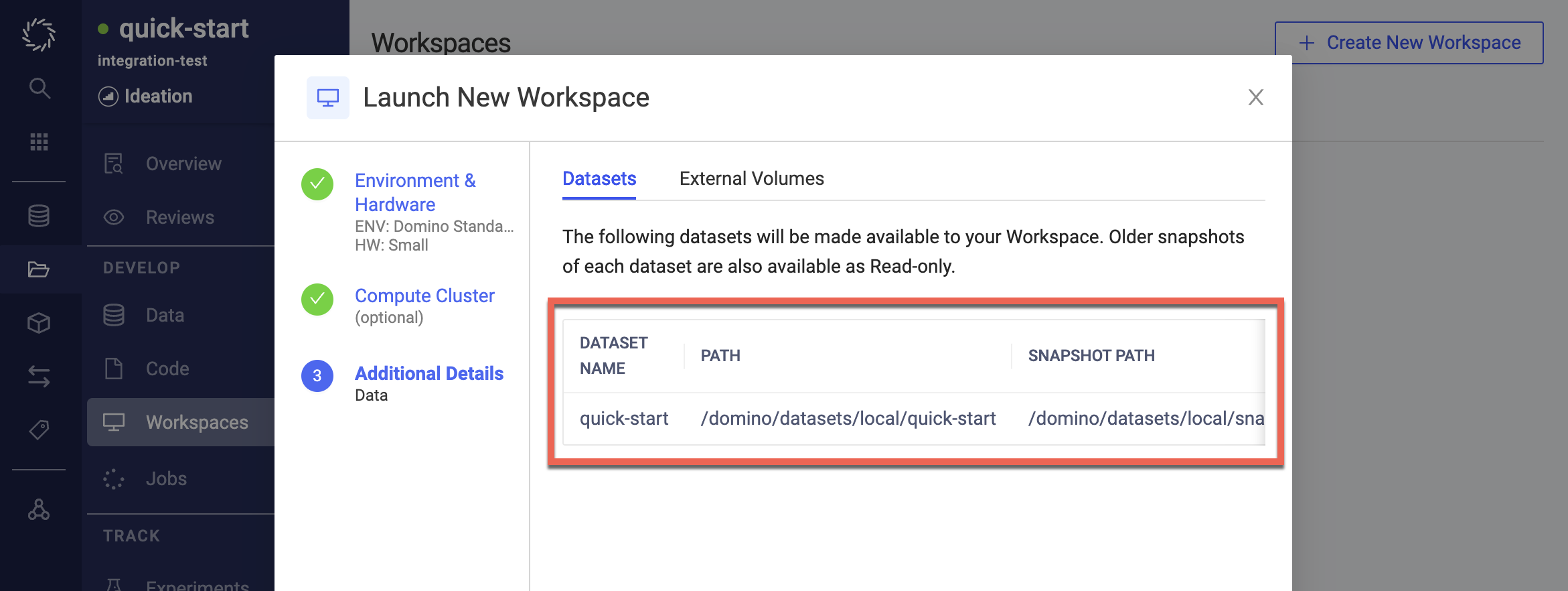
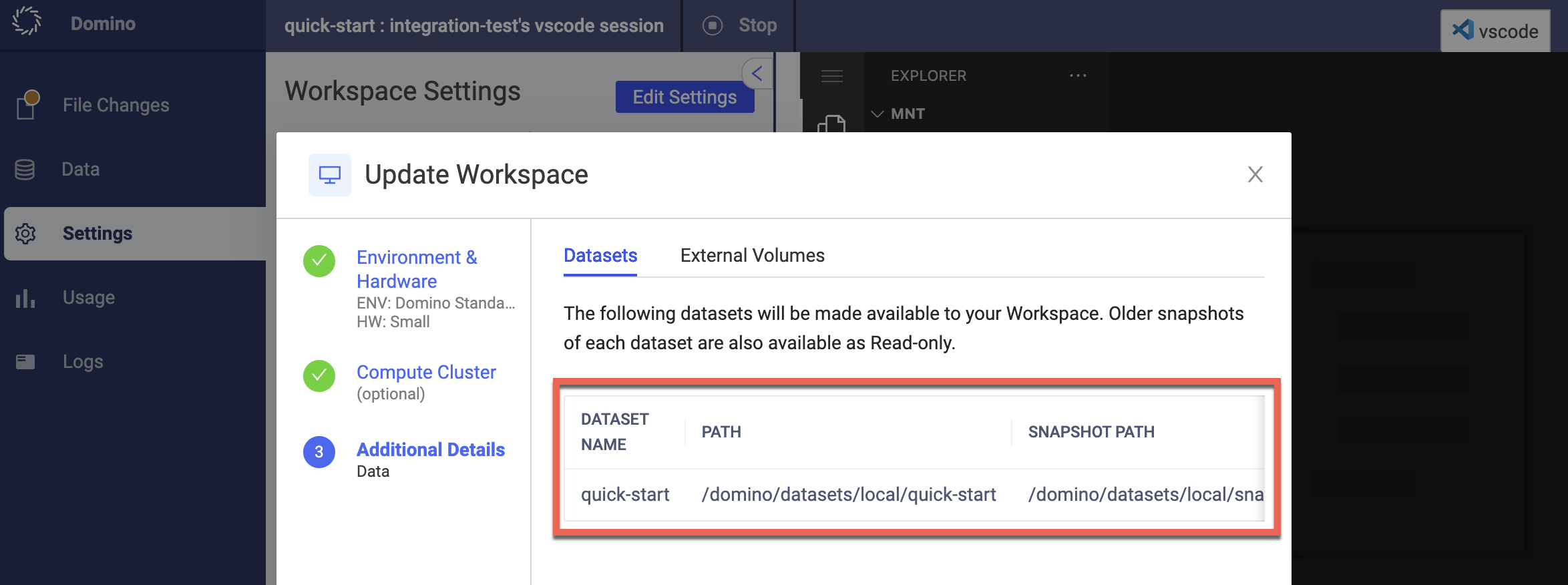
-
When launching a job, click Additional Details:
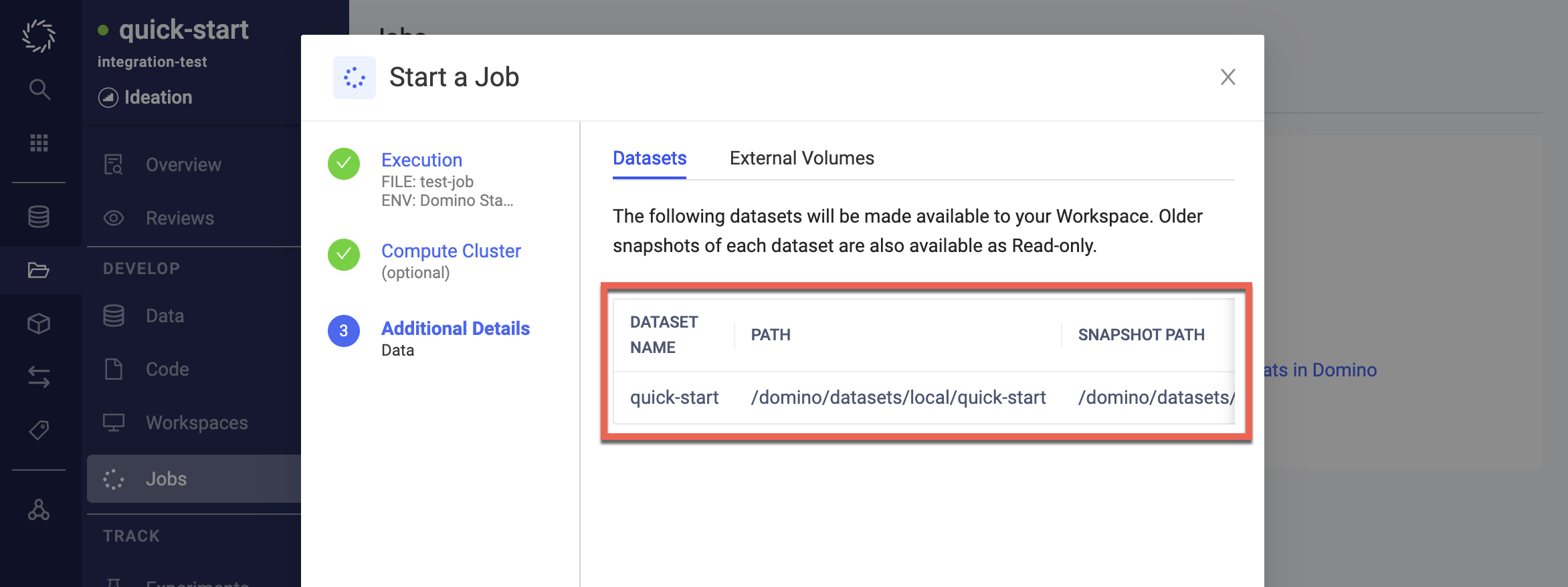
-
In a running job, click Details > Data.
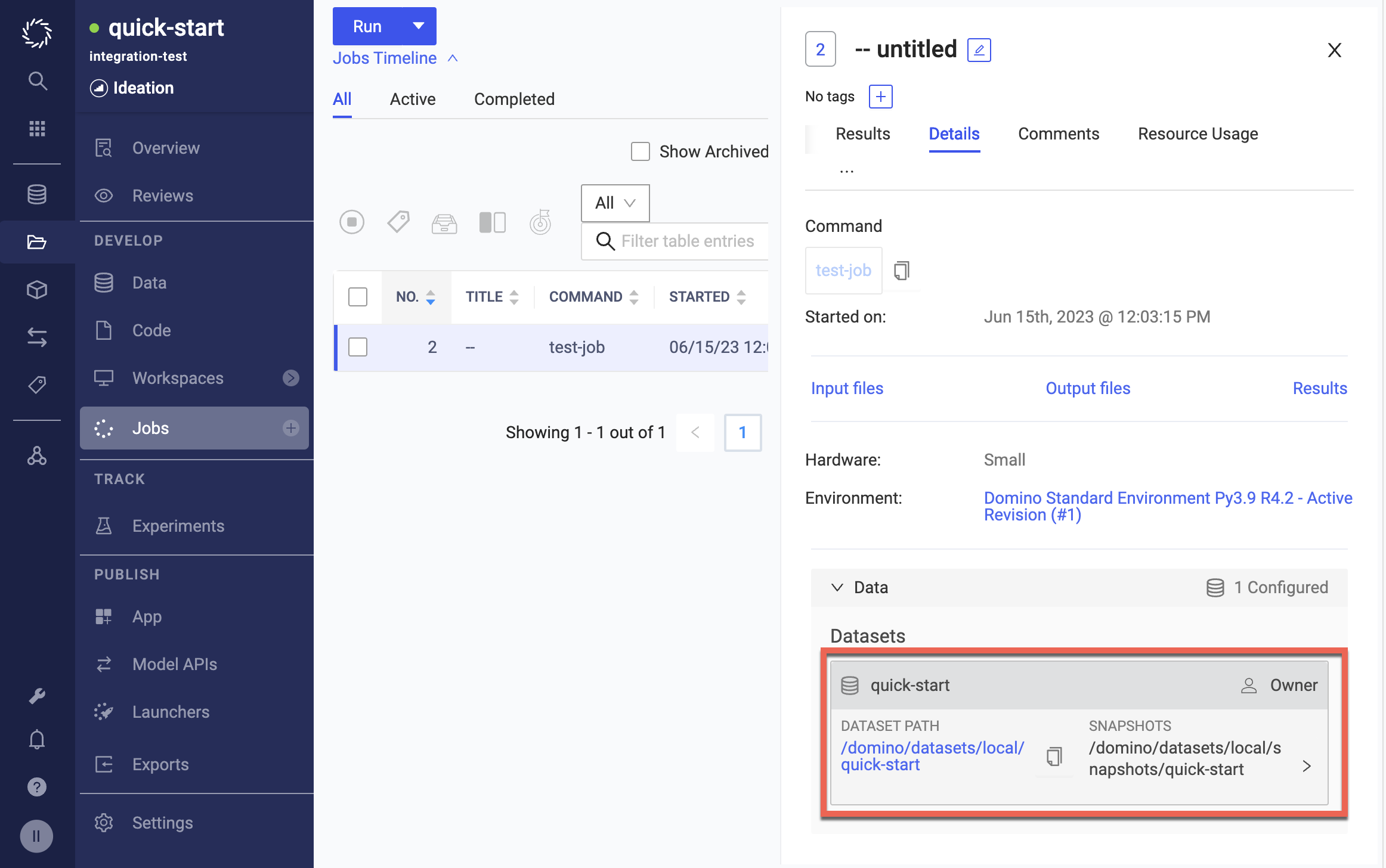
Domino executions (workspaces, jobs, apps, and launchers) automatically make Datasets and their associated snapshots from a project available in a predefined path that follows the conventions described in this topic. The following configuration demonstrates how it translates into paths that will be available in executions.
-
Dataset called
clapton(local to the project)-
Snapshot 1 (tagged with
tag1) -
Snapshot 2 (not tagged)
-
-
Dataset called
mingus(local to project)-
Snapshot 1 (tagged with
tag2) -
Snapshot 2 (not tagged)
-
-
Dataset called
ella(shared from another project)-
Snapshot 1 (tagged with
tag3) -
Snapshot 2 (not tagged)
-
-
Dataset called
davis(shared from another project)-
Snapshot 1 (tagged with
tag4) -
Snapshot 2 (not tagged)
-
For a Domino File System (DFS) project, Datasets and snapshots are available in the following hierarchy:
/domino
|--/datasets
|--/local <== Local datasets and snapshots
|--/clapton <== Read-write dataset
|--/mingus <== Read-write dataset
|--/snapshots <== Snapshot folder organized by dataset
|--/clapton <== Read-only Snapshots for clapton dataset
|--/tag1 <== Mounted under latest tag
|--/1 <== Always mounted under the snapshot number
|--/2
|--/mingus
|--/tag2
|--/1
|--/2
|--/ella <== Read-only shared dataset
|--/davis <== Read-only shared dataset
|--/snapshots <== Shared datasets snapshots organized by dataset
|--/ella
|--/tag3 <== Read-only snapshot for ella dataset
|--/1 <== Mounted under latest tag
|--/2 <== Always mounted under the snapshot number
|--/davis
|--/tag4
|--/1
|--/2For a Git-based Projects, the Datasets and snapshots are available in the following hierarchy:
/mnt
|--/data
|--/clapton <== Read-write dataset
|--/mingus <== Read-write dataset
|--/snapshots <== Snapshot folder organized by dataset
|--/clapton <== Read-only snapshots for clapton dataset
|--/tag1 <== Mounted under latest tag
|--/1 <== Always mounted under the snapshot number
|--/2
|--/mingus
|--/tag2
|--/1
|--/2
|--/imported
|--/data
|--/ella <== Read-only shared dataset
|--/davis <== Read-only shared dataset
|--/snapshots <== Snapshot folder organized by dataset
|--/ella <== Read-only Snapshots for ella dataset
|--/tag3 <== Mounted under latest tag
|--/1 <== Always mounted under the snapshot number
|--/2
|--/davis
|--/tag4
|--/1
|--/2-
Create and manage Dataset snapshots for data reproducibility.
-
Learn about Dataset best practices.